Code
library(tidyverse)
library(vroom)
library(infer)Simulación y ejemplo con créditos agropecuarios
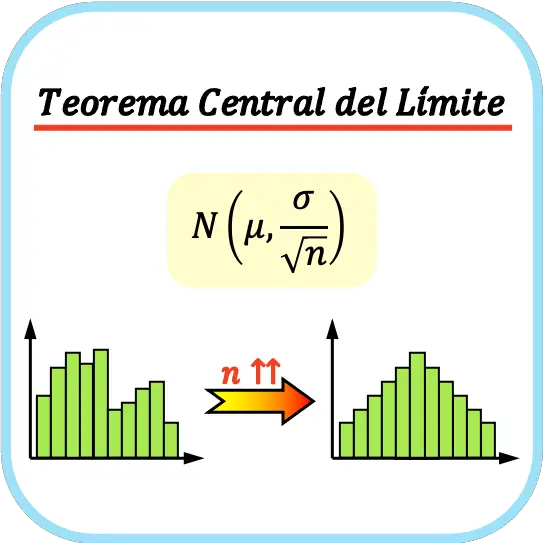
library(tidyverse)
library(vroom)
library(infer)# Función para simular lanzamientos de moneda
simular_monedas <- function(n) {
resultados <- sample(c("Cara", "Sello"), n, replace = TRUE)
prop.table(table(resultados))
}
# Tamaños de muestra
tamanos_muestra <- seq(from = 10, to = 100000, by = 100)
resultados <- data.frame(tamaño = integer(),
caras = numeric(),
sellos = numeric())
# Simulaciones
for (n in tamanos_muestra) {
proporciones <- simular_monedas(n)
resultados <- resultados |>
add_row(tamaño = n,
caras = proporciones["Cara"],
sellos = proporciones["Sello"])
}
# Graficar resultados
ggplot(resultados, aes(x = tamaño)) +
geom_line(aes(y = caras, color = "Cara"), size = 1) +
geom_line(aes(y = sellos, color = "Sello"), size = 1) +
geom_hline(yintercept = 0.5,
linetype = "dashed",
color = "black") +
labs(
title = "Proporciones de cara y sello en función del tamaño de la muestra",
x = "Tamaño de la nuestra",
y = "Proporción",
color = "Resultado"
) +
scale_color_manual(values = c("Cara" = "blue", "Sello" = "red")) +
theme_minimal()
# Función para simular lanzamientos de un dado
simular_dados <- function(n) {
resultados <- sample(1:6, n, replace = TRUE)
prop.table(table(resultados))
}
# Tamaños de muestra
tamanos_muestra <- seq(from = 100, to = 10000, by = 10)
resultados_dado <- data.frame(
tamaño = integer(),
cara1 = numeric(),
cara2 = numeric(),
cara3 = numeric(),
cara4 = numeric(),
cara5 = numeric(),
cara6 = numeric()
)
# Realizar simulaciones
for (n in tamanos_muestra) {
proporciones <- simular_dados(n)
resultados_dado <- resultados_dado |>
add_row(
tamaño = n,
cara1 = ifelse("1" %in% names(proporciones), proporciones["1"], 0),
cara2 = ifelse("2" %in% names(proporciones), proporciones["2"], 0),
cara3 = ifelse("3" %in% names(proporciones), proporciones["3"], 0),
cara4 = ifelse("4" %in% names(proporciones), proporciones["4"], 0),
cara5 = ifelse("5" %in% names(proporciones), proporciones["5"], 0),
cara6 = ifelse("6" %in% names(proporciones), proporciones["6"], 0)
)
}
# Graficar resultados
resultados_long <- resultados_dado |>
pivot_longer(cols = starts_with("cara"),
names_to = "cara",
values_to = "proporcion")
ggplot(resultados_long, aes(x = tamaño, y = proporcion, color = cara)) +
geom_line(size = 1) +
geom_hline(yintercept = 1 / 6,
linetype = "dashed",
color = "black") +
labs(
title = "Proporciones de cada cara del dado en función del tamaño de la muestra",
x = "Tamaño de la Muestra",
y = "Proporción",
color = "Cara"
) +
theme_minimal() +
scale_color_manual(values = rainbow(6))
ruta_df_creditos <-
"../datos/Colocaciones_de_Cr_dito_Sector_Agropecuario_-_2021-_2024_20250502.csv"
df_creditos <- vroom(ruta_df_creditos)
df_creditos |> head()df_creditos$Genero |>
table() |>
prop.table()
H M S
0.58952160 0.35875894 0.05171946 Podemos tomar una muestra aleatoria de tamaño \(n\) del conjunto de df_creditos total. En este caso a manera de ejemplo usamos \(n = 50\):
n_muestra <- 50
set.seed(2024)
muestra_virtual1 <-
df_creditos |>
rep_sample_n(size = n_muestra)
muestra_virtual1Después podemos contar cuántas personas de la muestra simulada tienen la etiqueta “Sí” y obtener la proporción:
muestra_virtual1 |>
mutate(resultado = Genero == "M") |>
reframe(total_si = sum(resultado),
proporcion_si = total_si / n_muestra)Podríamos concluir basados en esta muestra virtual que la estimación del porcentaje de créditos otorgados a mujeres es del 40%.
Podemos generar \(k\) muestreos aleatorios simulados con el mismo tamaño de muestra \(n\):
k_replicas <- 100
set.seed(2025)
muestra_virtual_100 <-
df_creditos |>
rep_sample_n(size = n_muestra, reps = k_replicas)
muestra_virtual_100En la base de df_creditos previa tenemos en total \(5000\) registros que son el resultado de \(n \times k = 50 \times 100 = 5000\). Ahora resumamos con la proporción de cada réplica:
resumen_muestreo_100 <-
muestra_virtual_100 |>
mutate(resultado = Genero == "M") |>
group_by(replicate) |>
reframe(total_si = sum(resultado)) |>
mutate(proporcion_si = total_si / n_muestra)
resumen_muestreo_100Finalmente podemos graficar la distribución de la proporción estimada de mujeres a las que se les otorgan créditos:
promedio_prop_mujer <-
resumen_muestreo_100$proporcion_si |>
mean()
resumen_muestreo_100 |>
ggplot(aes(x = proporcion_si)) +
geom_histogram(color = "black", binwidth = 0.02) +
geom_vline(xintercept = promedio_prop_mujer, lty = 2, color = "red") +
labs(title = "Proporción estimada con 100 réplicas",
subtitle = "Tamaño de muestra = 50",
x = "Proporción",
y = "Frecuencia")
¿Por qué observamos que en algunas muestras obtenemos valores más altos o más bajos que la proporción de referencia 0.35875894? 🤔🤔🤔
# Muestra de tamaño 20
set.seed(2025)
muestra_n20 <-
df_creditos |>
rep_sample_n(size = 20, reps = 100, replace = TRUE) |>
mutate(resultado = Genero == "M") |>
group_by(replicate) |>
reframe(total_si = sum(resultado)) |>
mutate(proporcion_si = total_si / 20,
N = 20)
# Muestra de tamaño 50
set.seed(2025)
muestra_n50 <-
df_creditos |>
rep_sample_n(size = 50, reps = 100, replace = TRUE) |>
mutate(resultado = Genero == "M") |>
group_by(replicate) |>
reframe(total_si = sum(resultado)) |>
mutate(proporcion_si = total_si / 50,
N = 50)
# Muestra de tamaño 100
set.seed(2025)
muestra_n100 <-
df_creditos |>
rep_sample_n(size = 100, reps = 100, replace = TRUE) |>
mutate(resultado = Genero == "M") |>
group_by(replicate) |>
reframe(total_si = sum(resultado)) |>
mutate(proporcion_si = total_si / 100,
N = 100)
# Muestra de tamaño 1000
set.seed(2025)
muestra_n1000 <-
df_creditos |>
rep_sample_n(size = 1000, reps = 100, replace = TRUE) |>
mutate(resultado = Genero == "M") |>
group_by(replicate) |>
reframe(total_si = sum(resultado)) |>
mutate(proporcion_si = total_si / 1000,
N = 1000)
# Muestra de tamaño 10000
set.seed(2025)
muestra_n10000 <-
df_creditos |>
rep_sample_n(size = 10000, reps = 100, replace = TRUE) |>
mutate(resultado = Genero == "M") |>
group_by(replicate) |>
reframe(total_si = sum(resultado)) |>
mutate(proporcion_si = total_si / 10000,
N = 10000)
# Muestra de tamaño 100000
set.seed(2025)
muestra_n100000 <-
df_creditos |>
rep_sample_n(size = 100000, reps = 100, replace = TRUE) |>
mutate(resultado = Genero == "M") |>
group_by(replicate) |>
reframe(total_si = sum(resultado)) |>
mutate(proporcion_si = total_si / 100000,
N = 100000)
bind_rows(muestra_n20, muestra_n50, muestra_n100,
muestra_n1000, muestra_n10000, muestra_n100000) |>
select(proporcion_si, N) |>
ggplot(aes(x = proporcion_si)) +
facet_wrap(~N, ncol = 3, scales = "free") +
geom_histogram(color = "white") +
geom_vline(xintercept = 0.35875894, color = "red")
data.frame(
muestra = c(20, 50, 100, 1000, 10000, 100000),
desviacion = c(
sd(muestra_n20$proporcion_si),
sd(muestra_n50$proporcion_si),
sd(muestra_n100$proporcion_si),
sd(muestra_n1000$proporcion_si),
sd(muestra_n10000$proporcion_si),
sd(muestra_n100000$proporcion_si)
)
)
