Code
library(tidyverse)
library(infer)Intervalos de confianza con bootstrapping

library(tidyverse)
library(infer)
library(tidyverse)
library(infer)
library(ggpubr)set.seed(2024)
peso_tomates <- rnorm(n = 10, mean = 71.34, sd = 4.5)
sample(peso_tomates, size = 10, replace = TRUE) [1] 66.29392 73.44922 66.29392 76.55144 75.75886 70.85413 65.82806 75.75886
[9] 70.76834 70.38205datos <- read_csv("datos/EncuestasColombia2022-Update.csv")
datos |> head()df_encuesta <-
read_csv("datos/Encuesta de clase - Diseño Experimental.csv", col_types = "cccc") |>
set_names(c("fecha", "prom_acad", "trabajo", "numero")) |>
mutate(prom_acad = str_replace_all(prom_acad, ",", "."),
prom_acad = as.numeric(prom_acad),
fecha = as.POSIXct(fecha)) |>
filter(prom_acad <= 5)
df_encuesta |> head()datos |>
ggplot(aes(x = gustavo_petro)) +
geom_histogram(bins = 10, color = "black")
ggqqplot(datos$gustavo_petro)

inferspecify()generate()calculate()visualize()get_confidence_interval(). Nota: para mejorar la visualización de los intervalos de confianza, se puede utilizar la función shade_confidence_interval()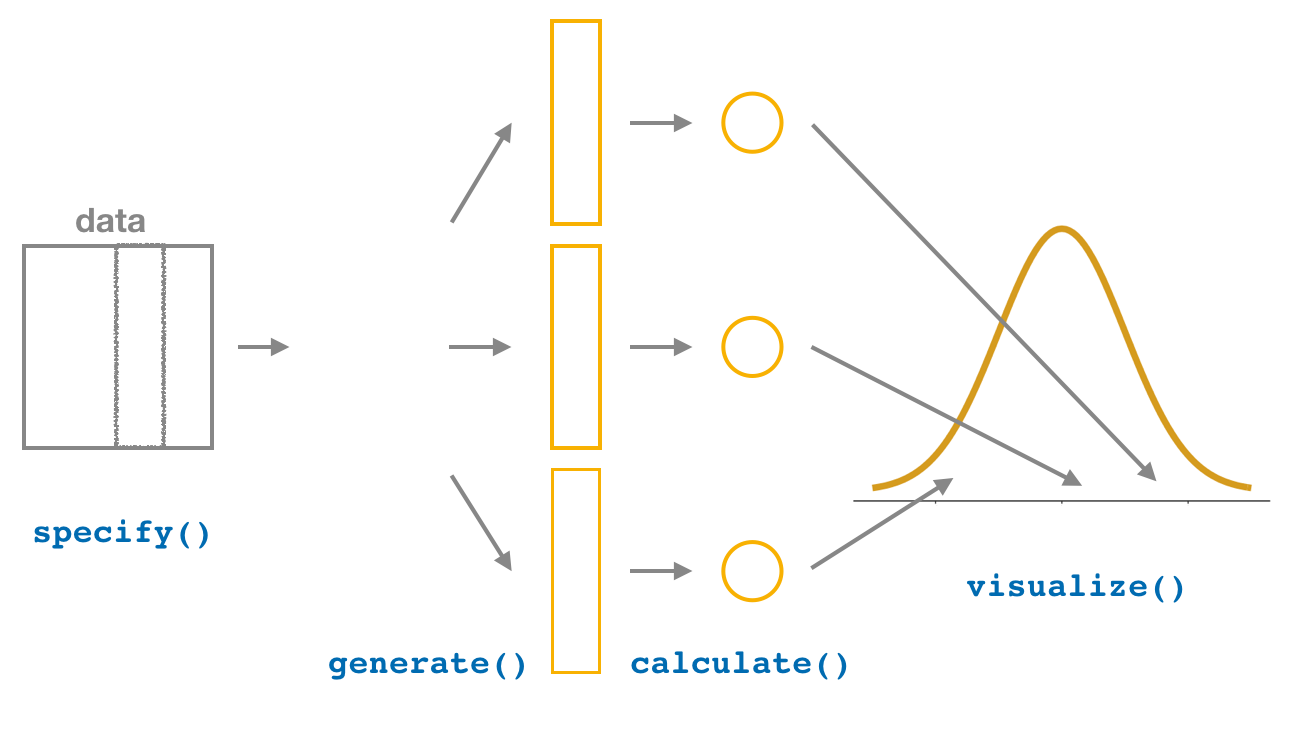
media_muestral <- datos$gustavo_petro |>mean(na.rm = TRUE)
media_muestral[1] 34.05121set.seed(2024)
remuestreo <- datos |>
specify(response = gustavo_petro) |>
generate(reps = 1000, type = "bootstrap") |>
calculate(stat = "mean")
remuestreoremuestreo |>
visualize()
# Usamos 0.975 porque --> 1 - 0.025 = 0.975 --> Área a la derecha
quantile(remuestreo$stat, probs = c(0.025, 0.975)) 2.5% 97.5%
31.13422 36.87931 ic_percentil <-
remuestreo %>%
get_confidence_interval(level = 0.95, type = "percentile")
ic_percentil\[\bar{X} \pm z \times Error\ Estándar\]
valor_z <- qnorm(p = 0.025) |> abs()
promedio_remuestreo <- mean(remuestreo$stat)
desv_remuestreo <- sd(remuestreo$stat)
lim_inferior <- promedio_remuestreo - (valor_z * desv_remuestreo)
lim_superior <- promedio_remuestreo + (valor_z * desv_remuestreo)
c(lim_inferior, lim_superior)[1] 31.25111 36.94721ic_ee <-
remuestreo %>%
get_confidence_interval(level = 0.95,
type = "se",
point_estimate = promedio_remuestreo)
ic_eetotal_votantes <- 21279308
(total_votantes * 31.13422) / 100[1] 6625147(total_votantes * 36.87931) / 100[1] 7847662remuestreo %>%
visualize() +
shade_confidence_interval(endpoints = ic_percentil) +
geom_vline(
xintercept = media_muestral,
color = "red",
lty = 2,
size = 1.5
) +
geom_vline(
xintercept = mean(remuestreo$stat),
color = "black",
lty = 2,
size = 1.5
)
\[\bar{X} - t_{\alpha/2, n-1}\frac{S}{\sqrt{n}} < \mu < \bar{X} + t_{\alpha/2, n-1}\frac{S}{\sqrt{n}}\]
t.test(x = datos$gustavo_petro,
conf.level = 0.95)
One Sample t-test
data: datos$gustavo_petro
t = 23.011, df = 57, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
31.08799 37.01442
sample estimates:
mean of x
34.05121 n_datos <- datos$gustavo_petro |> na.omit() |> length()
desv_muestral <- datos$gustavo_petro |> sd(na.rm = TRUE)
estadistico_t <- qt(p = 0.025, df = n_datos-1) |> abs()
media_muestral - (estadistico_t * (desv_muestral / sqrt(n_datos) ) )[1] 31.08799media_muestral + (estadistico_t * (desv_muestral / sqrt(n_datos) ) )[1] 37.01442df_encuesta$trabajo |>
table() |>
prop.table()
No Sí
0.6129032 0.3870968 set.seed(2024)
remuestreo_trabajo <- df_encuesta %>%
specify(response = trabajo, success = "Sí") %>%
generate(reps = 1000, type = "bootstrap") %>%
calculate(stat = "prop")
remuestreo_trabajoremuestreo_trabajo |>
visualize()
ic_perc_trabajo <-
remuestreo_trabajo %>%
get_confidence_interval(level = 0.95, type = "percentile")
ic_perc_trabajoremuestreo_trabajo |>
visualize() +
shade_confidence_interval(endpoints = ic_perc_trabajo)
\[\hat{p}-Z_{\alpha/2}\sqrt{\frac{\hat{p}(1-\hat{p})}{n}} < p < \hat{p}+Z_{\alpha/2}\sqrt{\frac{\hat{p}(1-\hat{p})}{n}}\]
df_encuesta |>
count(trabajo)total_muestra <- df_encuesta |> nrow()
total_trabajo <- 12
proporcion_referencia <- 0.5
prop.test(x = total_trabajo, n = total_muestra, p = proporcion_referencia)
1-sample proportions test with continuity correction
data: total_trabajo out of total_muestra, null probability proporcion_referencia
X-squared = 1.1613, df = 1, p-value = 0.2812
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.2241645 0.5771290
sample estimates:
p
0.3870968 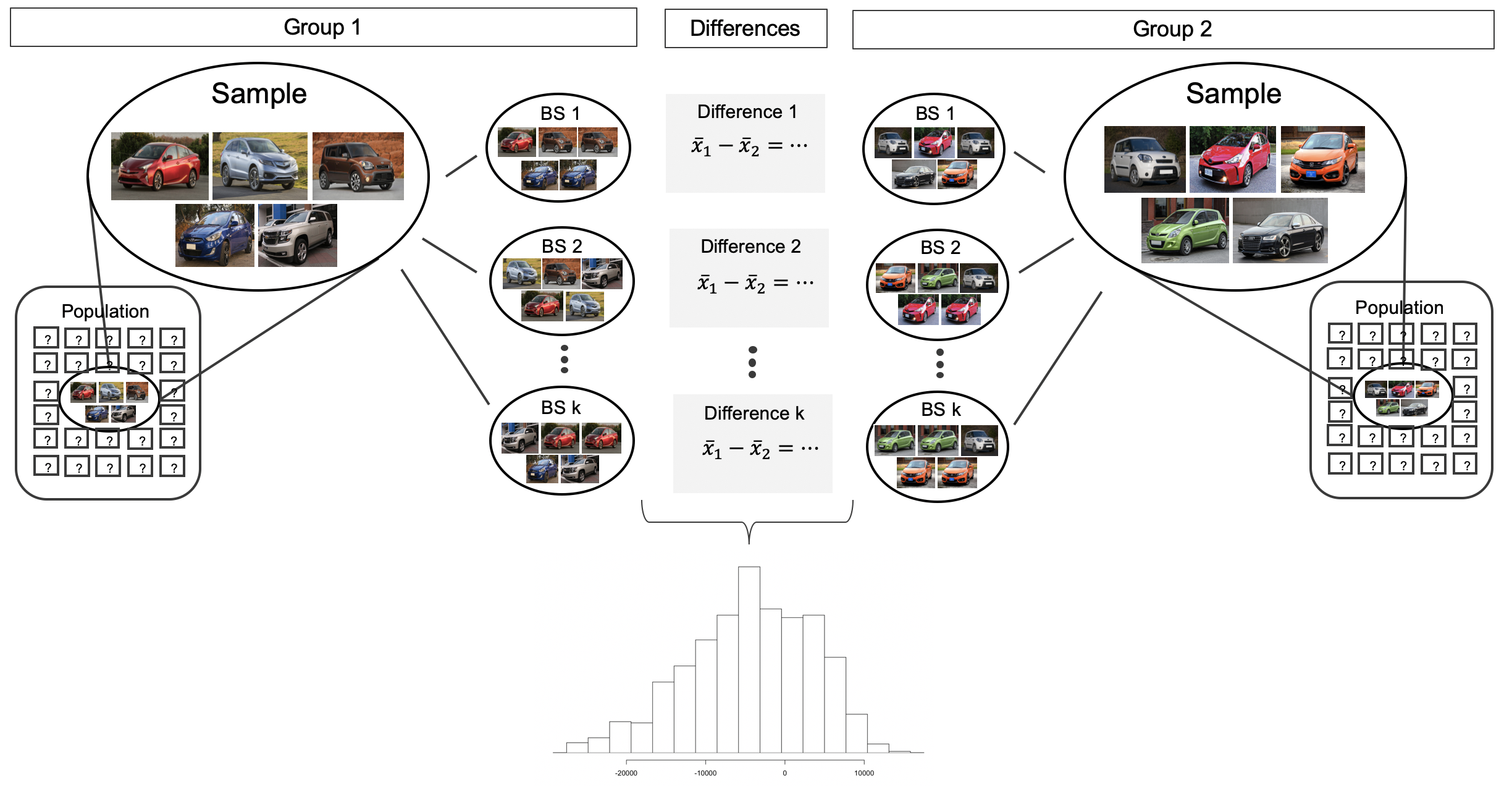
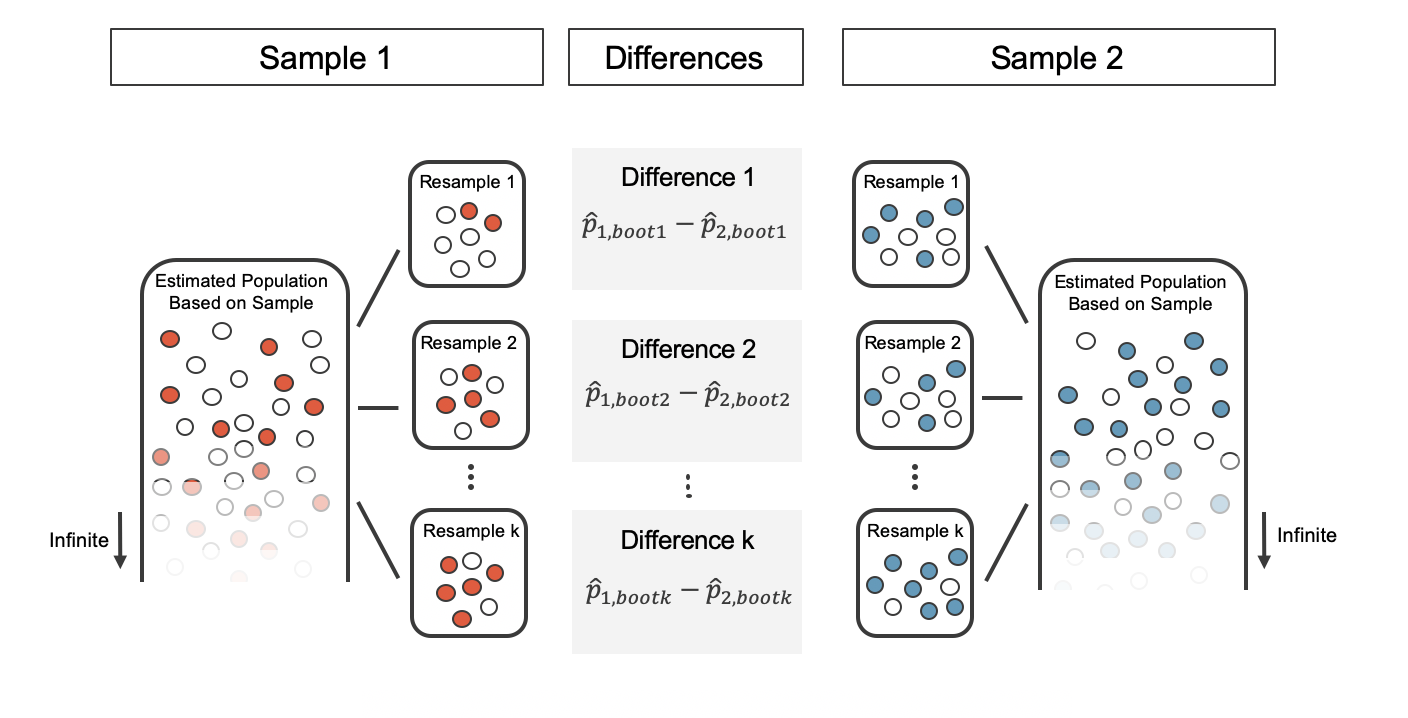
medias_muestrales <-
df_encuesta |>
group_by(trabajo) |>
reframe(promedio = mean(prom_acad))
medias_muestralesmedia_no <- medias_muestrales |> filter(trabajo == "No") |> pull(promedio)
media_si <- medias_muestrales |> filter(trabajo == "Sí") |> pull(promedio)
diferencia_muestral <- media_si - media_no
diferencia_muestral[1] 0.01890351set.seed(2024)
remuestreo_dif_medias <- df_encuesta |>
specify(formula = prom_acad ~ trabajo) |>
generate(reps = 1000, type = "bootstrap") |>
calculate(stat = "diff in means", order = c("Sí", "No"))
remuestreo_dif_mediasremuestreo_dif_medias |>
visualize()
ic_dif_medias <-
remuestreo_dif_medias |>
get_confidence_interval(level = 0.95,
type = "percentile")
ic_dif_mediasremuestreo_dif_medias %>%
visualize() +
shade_confidence_interval(endpoints = ic_dif_medias) +
geom_vline(
xintercept = diferencia_muestral,
color = "red",
lty = 2,
size = 1.5
) +
geom_vline(
xintercept = mean(remuestreo_dif_medias$stat),
color = "black",
lty = 2,
size = 1.5
)
t.test(df_encuesta$prom_acad ~ df_encuesta$trabajo,
mu = 0,
conf.level = 0.95)
Welch Two Sample t-test
data: df_encuesta$prom_acad by df_encuesta$trabajo
t = -0.19683, df = 21.603, p-value = 0.8458
alternative hypothesis: true difference in means between group No and group Sí is not equal to 0
95 percent confidence interval:
-0.218288 0.180481
sample estimates:
mean in group No mean in group Sí
3.985263 4.004167

\[z = \frac{x - \mu}{\sigma}\]
media_prom <- df_encuesta$prom_acad |> mean()
desv_prom <- df_encuesta$prom_acad |> sd()
(df_encuesta$prom_acad - media_prom) / desv_prom [1] 0.02969807 -0.77085856 -2.37197180 -0.37058024 0.42997638 -0.77085856
[7] 0.02969807 -1.17113687 0.02969807 0.42997638 0.83025469 0.83025469
[13] -0.37058024 1.63081132 -0.77085856 0.83025469 -0.37058024 0.02969807
[19] -1.17113687 -0.37058024 0.02969807 0.02969807 0.42997638 -0.29052458
[25] -0.77085856 0.79022686 1.63081132 2.03108963 0.83025469 -2.13180481
[31] 0.83025469valor_z <- (4.1 - media_prom) / desv_prom1 - pnorm(q = valor_z, mean = 0, sd = 1)[1] 0.33360641 - pnorm(q = 4.1, mean = media_prom, sd = desv_prom)[1] 0.3336064media_voto <- datos$gustavo_petro |> mean(na.rm = TRUE)
desv_voto <- datos$gustavo_petro |> sd(na.rm = TRUE)
(datos$gustavo_petro - media_voto) / desv_voto [1] 0.527857982 0.980399474 0.341517367 0.616591608 0.155176753
[6] 0.947568032 0.581098157 0.350390730 0.229712999 0.527857982
[11] 0.208416929 0.847299035 0.350390730 0.758565409 -0.004543774
[16] -0.004543774 0.217290291 -0.182011025 0.261657104 0.936032661
[21] 0.714198596 0.101936577 -0.119897487 -0.528072166 -0.625679155
[26] -0.625679155 -0.803146407 -0.767652956 -1.069347284 -0.714412781
[31] -1.273434624 -1.513015414 -1.104840735 -0.341731552 -1.158080910
[36] -0.332858189 -1.193574361 -0.803146407 -0.874133307 0.377010818
[41] -0.980613658 -1.335548162 -0.723286143 -1.832456467 -1.601749040
[46] -1.557382227 -0.279618014 -1.424281788 -0.102150762 1.104626550
[51] NA 1.424067603 2.107316523 1.991962809 NA
[56] NA 1.654775031 1.628154943 0.572224795 NA
[61] 1.415194241 1.947595996 NA NA NA1 - pnorm(q = 50, mean = media_voto, sd = desv_voto)[1] 0.07850578