Code
library(tidyverse)
library(janitor)
library(readxl)Estadística
library(tidyverse)
library(janitor)
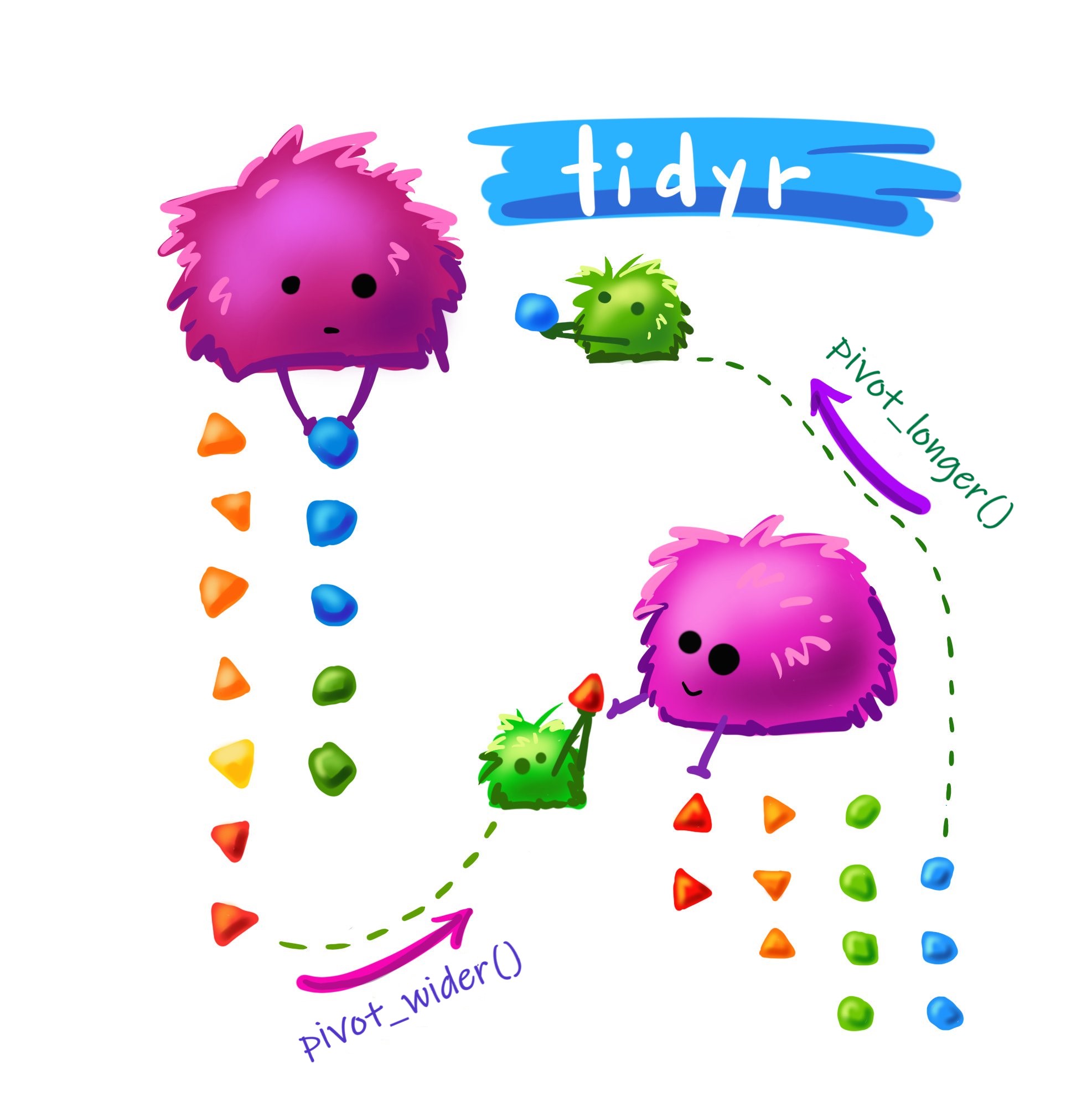
library(readxl)tidyr![]()
pivot_longer() y pivot_wider()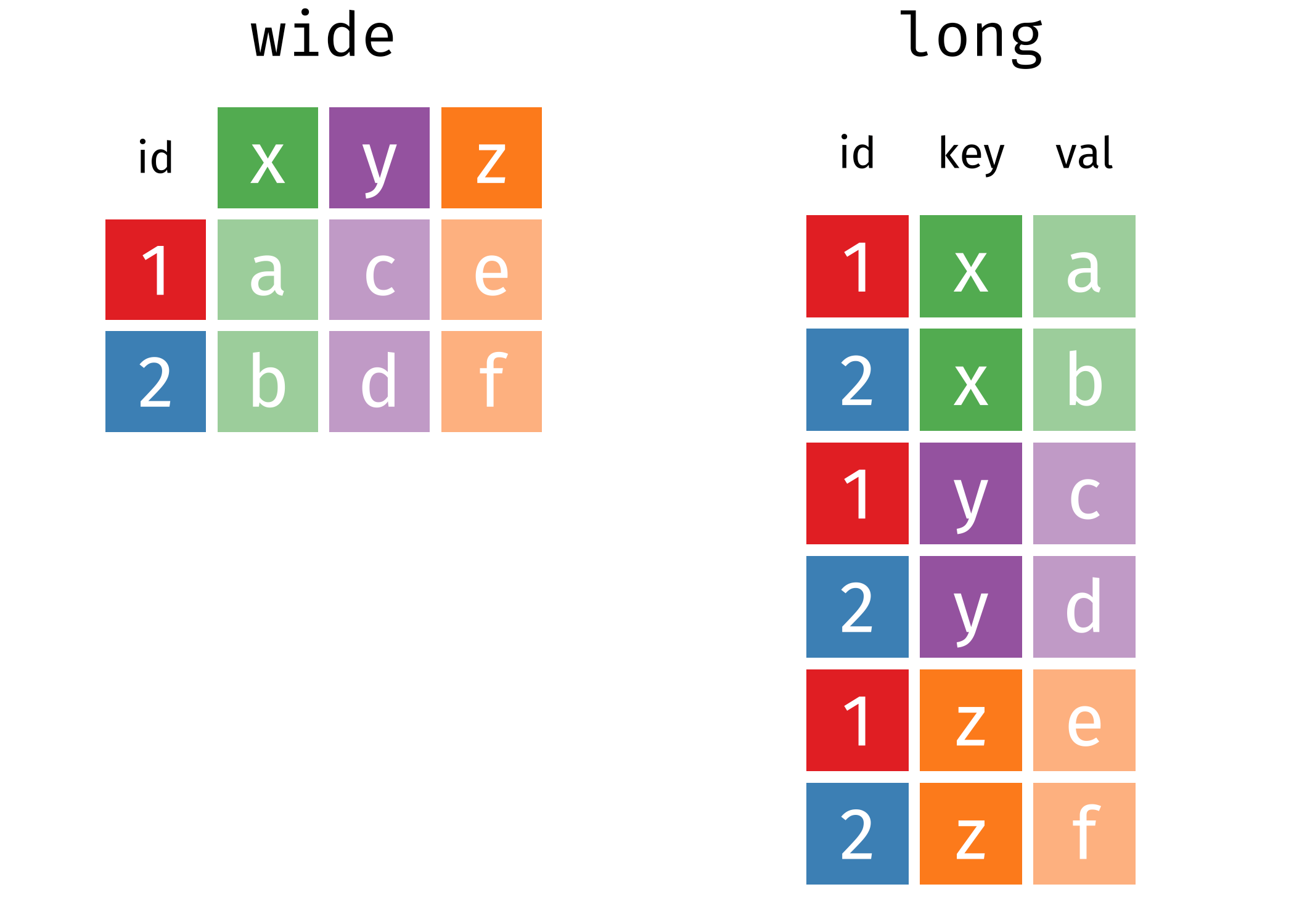
dplyr![]()


df_costos <-
read_excel(
"datos-ejemplos/datos-desordenados/COSTOS POR HECTÁREA DE ARROZ, SISTEMA RIEGO, NACIONAL, I SEMESTRE.xlsx",
skip = 1
)
df_costosdf_costos_ordenado <-
df_costos |>
slice(-c(9, 10)) |>
pivot_longer(cols = -RUBRO,
names_to = "year_es",
values_to = "costo") |>
rename(rubro = RUBRO) |>
mutate(rubro = str_to_sentence(rubro))
df_costos_ordenadodf_costos_ordenado |>
group_by(year_es) |>
reframe(total_costo = sum(costo))df_costos_ordenado |>
pivot_wider(names_from = year_es,
values_from = costo)df_hortalizas <-
read_csv("datos-ejemplos/datos-desordenados/PRODUCCI_N_EN_TONELADAS_DE_CULTIVOS_DE_HORTALIZAS__EN_EL_VALLE_DEL_CAUCA_20240312.csv")
df_hortalizasdf_hortalizas_ordenada <-
df_hortalizas |>
pivot_longer(
cols = -c(Municipios, Año),
names_to = "cultivo",
values_to = "produccion"
) |>
mutate(cultivo = str_replace_all(cultivo, " [aA|bB]", "")) |>
filter(Municipios != "TOTAL")
df_hortalizas_ordenada |> head()df_bovinos_desordenada <-
read_csv(
"datos-ejemplos/datos-desordenados/Inventario_Poblacional_Del_Ganado_Bovino_Valle_del_Cauca_20240312.csv"
)
df_bovinos_desordenada |> head()df_bovinos_ordenada <-
df_bovinos_desordenada |>
pivot_longer(
cols = -c(Municipio, Año, `Unidades Productoras`),
names_to = "variable",
values_to = "bovinos"
) |>
separate(
variable,
into = c("sexo", "edad", "otra"),
sep = " ",
remove = TRUE
) |>
select(-otra) |>
filter(sexo != "Total") |>
mutate(edad = str_replace_all(edad, ">", ">36"),
edad = if_else(edad == "", "0-12", edad))
df_bovinos_ordenada |> head()df_area_sembrada_desord <-
read_csv(
"datos-ejemplos/datos-desordenados/Superficie_Sembrada_con_Ra_ces_Bulbos_y_Tub_rculos_en_el_departamento_del_Valle_del_Cauca_20240312.csv"
)
df_area_cosechada_desord <-
read_csv(
"datos-ejemplos/datos-desordenados/Superficie_Cosechada_con_Ra_ces_Bulbos_y_Tub_rculos__en_el_Departamento_del_Valle_del_Cauca_20240312.csv"
)
df_produccion_desord <-
read_csv(
"datos-ejemplos/datos-desordenados/Producci_n_en_Toneladas_por_Hect_reas_de_Ra_ces_Bulbos_y_Tub_rculos_en_el_Departamento_del_Valle_del_Cauca_20240312.csv"
)
df_rto_desord <-
read_csv(
"datos-ejemplos/datos-desordenados/Rendimiento_en_toneladas_por_hect_reas_en_Cultivos_de__Ra_ces_Bulbos_y_Tub_rculos_en_el_departamento_del_Valle_del_Cauca_20240312.csv"
)df_area_sembrada_ordenada <-
df_area_sembrada_desord |>
filter(Municipios != "TOTAL") |>
pivot_longer(
cols = -c(Municipios, año),
names_to = "cultivo",
values_to = "area_sembrada"
) |>
mutate(area_sembrada = as.numeric(area_sembrada))
df_area_cosechada_ordenada <-
df_area_cosechada_desord |>
filter(Municipios != "TOTAL") |>
pivot_longer(
cols = -c(Municipios, año),
names_to = "cultivo",
values_to = "area_cosechada"
) |>
mutate(area_cosechada = as.numeric(area_cosechada))
df_produccion_ordenada <-
df_produccion_desord |>
filter(Municipios != "TOTAL") |>
pivot_longer(
cols = -c(Municipios, año),
names_to = "cultivo",
values_to = "produccion"
) |>
mutate(produccion = as.numeric(produccion))
df_rto_ordenada <-
df_rto_desord |>
filter(Municipios != "TOTAL") |>
pivot_longer(
cols = -c(Municipios, año),
names_to = "cultivo",
values_to = "rendimiento"
) |>
mutate(rendimiento = as.numeric(rendimiento))df_total_odenada <-
left_join(
x = df_area_sembrada_ordenada,
y = df_area_cosechada_ordenada,
by = c("Municipios", "año", "cultivo")
) |>
left_join(y = df_produccion_ordenada,
by = c("Municipios", "año", "cultivo")) |>
left_join(y = df_rto_ordenada,
by = c("Municipios", "año", "cultivo")) |>
distinct(Municipios, año, cultivo, .keep_all = TRUE)
df_total_odenada |> head()write_csv(df_total_odenada, "ejemplo_exportar.csv")